Points as queries: Weakly semi-supervised object detection by points
Liangye Chen et al. / Points as Queries- Weakly Semi-supervised Object Detection by Points / CVPR-2021
저는 현재 공사현장에서 낙상 예방을 위해 safety harness(안전조끼)와 lifeline(안전선)을 실시간으로 탐지하는 프로젝트를 진행하고 있습니다. 물체 탐지 방법으로 지도학습 기반의 딥러닝을 활용하려고 하는데, 이를 위해서는 라벨링된 데이터셋이 필요합니다. 현재 온라인 상에는 라벨링 작업이 이미 된 데이터셋들이 많이 존재합니다. 그러나, 저희가 원하는 safety harness와 lifeline관련 데이터셋은 존재하지 않았습니다. 따라서 직접 데이터셋을 수집하고, 수작업으로 라벨링을 진행해야 했습니다.
700장이 넘는 사진에 바운딩 박스를 그리며 라벨링을 하다보니, 시간 비용이 많이 든다는 것을 느꼈습니다. 그래서, 라벨링 작업을 안하거나 줄일 수 있는 방법을 통해서 딥러닝을 학습시킬 수는 없을까하는 생각이 들었습니다.
그래서 이번에 소개드릴 논문은 2021년 CVPR에 발표된 논문으로, 적은 양의 fully-labeled images와 대다수의 weakly-labeled images by points로 구성된 데이터셋을 활용한 weakly semi-supervised 객체 탐지 방법을 제안합니다.
논문 링크 https://arxiv.org/abs/2104.07434
1. Problem Definition
이 논문은 지도학습 딥러닝을 위한 라벨링 작업 비용 문제를 해결하기 위해 점을 활용한 weakly annotated images로 구성된 데이터셋을 제안하고 있습니다. 이미지 수준(사진과 카테고리만 있는)의 데이터셋과 달리, 점 수준의 라벨링(물체 위에 점과 카테고리가 있는)은 라벨링 작업 비용도 줄이고 객체 수준의 정보는 제공하여 객체 탐지에 적절하다는 점입니다.
또한, 이런 데이터셋을 기반으로, 기존의 객체 탐지 방법의 단점을 해결한 새로운 방법인 PointDETR을 제안합니다. 제안된 방법은 객체 내 점들을 입력값으로 받고, 이 점들을 object queries로 변환하고, queries에 대한 object box을 예측합니다. 제안된 방법은 점으로 라벨링된 데이터셋에 적합하고, weakly semi-supervised detection task의 효율성을 잘 보여주고 있습니다.
2. Motivation
객체 탐지는 컴퓨터 비전에서 중요한 문제 중 하나입니다. 그러나, 많은 양의 데이터를 라벨링하기에는 시간이 많이 소요됩니다. 예를 들어, 각각의 객체 당 정교한 바운딩 박스를 라벨링하는데 10-35초 정도 걸립니다.
따라서, 데이터 라벨링 비용을 감소하기 위해 weakly supervised object detection(WSOD) 와 semi-supervised object detection(SSOD) 방법이 제안됩니다.

WSOD(weakly supervised object detection)는 이미지 수준의 라벨(카테고리만 있는)과 같은 weak annotations으로 된 많은 양의 데이터를 활용합니다. 이는 정교한 바운딩 박스보다 라벨링하기가 쉽습니다.

SSOD(semi-supervised object detection)는 작은 양의 box-level(바운딩 박스와 카테고리가 있는) labeled images와 많은 양의 라벨링 되지 않은 이미지로 모델을 학습합니다.
비록 이 방법들이 라벨링 비용은 낮췄지만, 성능은 여전히 지도학습에 비해 떨어집니다. 이에 대한 보완책으로, WSOD와 SSOD를 합친 weakly semi-supervised object detection methods(WSSOD) 가 연구되고 있습니다.

WSSOD는 작은 양의 box-level labeled images와 많은 양의 weakly labeled(여기서는 이미지 수준의 라벨링) images들을 활용합니다.
그러나, 이미지 수준의 라벨링은 모든 객체의 instance-level 정보를 갖고 있지 않기 때문에 객체 탐지에 적합하지 않습니다.
이에 대한 해결책으로, point을 통한 이미지 라벨링을 제안합니다.

point에 의한 이미지 라벨링은 2가지 장점이 있습니다.
image-level 라벨링과 비교했을 때, 점은 객체의 카테고리 뿐만 아니라, 객체 위치(instance position)의 사전 정보를 제공합니다
점 위치를 객체 중앙에 넣든, 가장자리에 넣든 크게 상관이 없습니다. 따라서, 라벨링 비용은 image-level 라벨링과 큰 차이가 없습니다
그러나, 현재 대부분의 탐지 모델들은 점 라벨링 기반으로 object box를 예측하는데 어려움을 겪습니다.
왜냐하면, 대부분 FPN(Feature Pyramid Network)을 기본 구성으로 하고 있습니다. FPN은 object box를 예측하기 위해 multi-level feature map을 사용하는데, point annotation은 single-level feature이기 때문입니다.
이에 대한 해결책으로, 본 연구는 DETR(detection with transformer)에 point encoder을 더한 새로운 탐지 모델인 Point DETR을 제안합니다. 새로운 모델은 라벨링된 점을 통해 정확하게 object boxes를 예측할 수 있습니다. 특히, object boxes를 예측하기 위해 single-level feature map을 사용합니다.
기존의 DETR과 다른 점은, 라벨링된 점의 위치와 카테고리를 point encoder을 통해 object queries로 인코딩한다는 것입니다. 이를 통해, 점과 object queries사이 일대일 대응관계를 만들 수 있습니다. 또한, 탐지 성능을 높이기 위해, 본 연구는 DETR처럼 box predictions을 바로 만들기 보단, 포인트 위치에 대한 파생점으로 상자 예측을 수행합니다.
모델의 우수성을 보이기 위해, MS-COCO데이터셋을 기준으로 다른 point-based detector인 FCOS와 비교했습니다.
주요 기여점 3가지는 다음과 같습니다
적은 양의 fully annotated images와 많은 양의 weakly annotated images by points로 구성된 weakly semi-supervised object detection task를 위한 새로운 데이터셋을 제안합니다. 이미지 수준의 이미지와 비교했을 때, 이 세팅은 instance-level 정보를 제공하고, 라벨링 비용도 차이가 없습니다.
위 데이터셋에 기반해서, 본 연구는 기존의 객체 탐지 모델의 단점을 분석하고, 쉽고 간단한 Point DETR을 제안합니다.
새로운 탐지 모델은 다양한 구성의 데이터셋에서 대부분의 탐지 모델보다 나은 성능을 보입니다.
3. Method
WSSOD(weakly semi-supervised object detection)은 적은 양의 instance-level(box-level) labled images와 많은 양의 weakly image-level labeled images를 훈련용 데이터로 사용합니다. 그러나, 이미지 수준의 라벨링된 사진은 객체 정보를 갖고 있지 않기 때문에 WSSOD에는 적합하지 않습니다.
그렇다면, 라벨링 비용 부담은 없는 새로운 방법은 없을까요?
본 연구는 weakly labeled images에 point annotation을 소개합니다. Point annotation은 weakly semantic segmentation에 사용되었지만, 객체 탐지에는 잘 활용되지 않았습니다.
객체 탐지에서, 본 연구는 point annotation을 다음과 같이 정의합니다:
객체 내 위치하고, 객체 클래스를 카테고리로 취급합니다.
즉, 객체를 (x,y,c) 로 표현할 수 있습니다. 본 연구에서는 point annotations은 객체 어디든지 위치할 수 있습니다. 이를 통해, 라벨링 비용 부담을 완화할 수 있습니다.
전체적인 프레임워크는 다음과 같습니다.
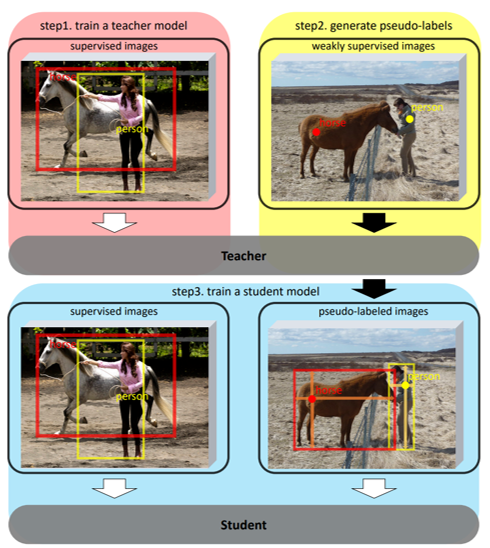
적은 양의 완전히 라벨링된 이미지와 많은 양의 점으로 라벨링된 이미지와 함께, 준지도학습에서 사용되는 self training을 훈련 기본값으로 설정합니다.
사용 가능한 라벨링된 이미지를 통해 teacher model을 훈련합니다
훈련된 teacher model을 활용하여 weakly point annotated images의 pseudo-labels을 만듭니다
Fully labeled images와 pseudo-labeled images로 student model을 훈련합니다
기존의 탐지 모델은 2가지 분류로 나뉩니다.
Multi-level detector(FCOS) : point annotations은 feature-level 정보가 없기 때문에, point annotation으로 object box를 예측하기 어렵습니다
Single-level detector(Faster R-CNN) : feature map levels을 선택하지 않아도 될지라도, bad performance나 point annotation에 엄격한 조건이 필요합니다.
3.1 Point DETR
point annotations을 가진 WSSOD에서 기존의 detector의 약점을 피하기 위해, 본 연구는 새로운 detector인 Point DETR을 제안합니다. 이는 point annotations을 object queries로 변환하고, 각각의 object query에서 image features을 추출하고, 그에 대응하는 object box를 결과로 냅니다.

우선, DETR에 대해 알아봅니다.
DETR은 end-to-end set-based object detector입니다. DETR은 CNN backbone, encoder-decoder transformer, prediction head로 구성되어 있습니다.
DETR은 먼저 CNN backbone에서 single-level 2D feature map을 추출하고, flatten하고, positional encoding으로 보충합니다. 그 다음, encoder-decoder transformer가 고정된 수의 object queries를 입력값으로 받고, 1D image feature embedding형태로 결과값을 산출합니다. 마지막으로, transformer의 output embeddings은 prediction head로 전달되어, 어떤 클래스에 속하는지 예측합니다.
Point DETR은 DETR의 많은 부분을 활용합니다. 다른 점은, Point DETR은 point encoder을 가집니다. Point encoder는 point annotations을 object queries로 인코딩합니다. DETR의 object queries와 달리, 이 object queries는 객체 instance의 position과 category를 포함하는 instance embeddings에 특수합니다. 그러므로, 이 object queries는 object instances와 일대일 대응을 가집니다. 게다가, object queries의 수는 DETR에서처럼 고정된 것이 아니라, 이미지 내 object instance의 수에 따라 변화합니다.
학습하는 동안, 각각의 object query의 loss를 Lbox라 정의합니다. 왜냐하면, 이미 카테고리는 있고, object box만 regress하면 되기 때문입니다. Lbox는 DETR에서 정의한 것과 같습니다.
Point encoder : point DETR에서, point annotations을 object queries로 인코딩하는 것은 point encoder에게 중요합니다.

point annotation(x,y,c) 는 2D 좌표 (x,y) 와 카테고리 인덱스 c로 분해됩니다. (x,y)에 근거해서, position embedding은 fixed spatial positional encodings에서 추출된다. category embedding은, category index c에 의해 미리 정의된 category embedding으로 부터 얻어집니다. 최종적으로, 이 sum operation을 통해 이 embedding을 합쳐서 object query를 얻습니다.
4. Experiment
Dataset
COCO 2017 detection dataset (118k training images, 5k val images)
Point annotated setting에 대해서, training images의 5%, 10%, 20%, 30%, 40%, 50% 를 fully labeled set로 하고, 나머지를 weakly labeled set으로 설정합니다
Weakly labeled set에 대해, 각각의 object에 대해 2가지 point annotation 방법이 있습니다
만약 object가 instance segmentation을 갖으면, instance mask로부터 point를 랜덤 추출한다
만약 안 갖으면, bounding box에서 point를 랜덤 추출한다
Training
2개의 모델 존재
Teach model : Point DETR, FCOS, Faster R-CNN
Student model : FCOS (student model은 teacher model의 효율성을 평가하는데만 사용됨)
Student model에 대해, student를 학습하기 위해 fully labeled images와 teacher model에 의해 생성된 pseudo-labeled images를 합칩니다
Results

Supervised는, student model을 fully annotated images로만 학습한 것입니다.
FCOS와 Point DETR이 Supervised보다 성능이 좋은 것으로 보아, pseudo-boxes로 인한 이점이 증명되었습니다. 즉**, point annotations이 있는 images가 detection task 성능을 향상시켰습니다.**
게다가, Point DETR이 FCOS보다 성능이 높았습니다.
Ablation study
Effect of Point Encoder

Positional embedding만 가진 point encoder가 catergory embedding만 가진 Point Encoder보다 성능이 높습니다.
즉, 본 연구의 방법은 오직 object boxes를 regress하기 때문에, positional embeddings없이 bounding box 관점에서 상대적인 point로 학습하기는 어렵다는 걸 보여줍니다
Catergory embedding을 통해서도 object shape같은 사전 정보를 제공하기 때문에 성능 향상에 기여합니다
Effect of Student Model
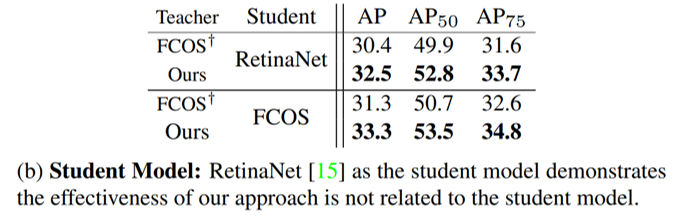
Student model로 FCOS와 RetinaNet을 비교하여 모델의 견고함을 비교했습니다
본 연구의 모델이 FCOS보다 2.1AP 높은 것을 통해, student model에 robust함을 알 수 있습니다
Comparison with another single-level detector

Single-level feature detector인 Faster R-CNN과 비교 결과, 본 연구의 모델이 1.9AP 높음을 알 수 있습니다
Effect of Point Location

객체 내 중심점과 중심점이 아닌 점의 위치 사이의 성능 비교 결과, 차이가 없었습니다
즉, 본 모델의 연구는 점의 위치와 robust합니다
Absolute vs. Relative Regression

본 연구의 방법은 object boxes을 예측하기 위해 relative regression을 사용했습니다
DETR에서는 Absolute regression을 사용했는데, 초록색 시계와 같이 점과 bouding box를 일치시키지 못합니다
Effect of Point Annotations

Point DETR은 mAP와 recall 관점에서 DETR보다 성능이 높음을 알 수 있습니다
Point annotations과 함께, 본 연구의 방법은 classification score의 quality로부터 방해를 받지 않습니다
DETR에서는 Absolute regression을 사용했는데, 초록색 시계와 같이 점과 bouding box를 일치시키지 못합니다
5. Conclusion
본 논문에서는 weakly semi-supervised detection task에서 point-annotations의 효율성을 보여주었습니다. 또한, point annotations이 기존의 detector와는 잘 맞지 않는다는 것을 보여주었습니다. 이를 해결하기 위해, 본 연구에서는 Point DETR 모델을 제안합니다. 기존의 DETR과 다르게, point encoder을 적용하여 point annotations과 objects 사이의 일대일 대응을 가능케 했습니다. 본 연구의 접근법은 간단하고 쉽게 적용가능하다는 장점이 있습니다. COCO 데이터셋을 활용하여 기존의 다른 모델과 비교하여 성능이 우수하다는 것을 보여주었습니다.
개인적인 의견
지도학습의 문제점인 라벨링 비용을 줄이고 성능은 유지하는 탐지 모델에 대해서 자세히 묘사되어 있어서 좋았습니다. Weakly semi-supervised object detection에서 이미지 수준의 weakly labeled images의 문제점을 해결하기 위해, 객체 탐지가 아니라 semantic segmentation에서 사용되었던 점 기반의 지도학습을 활용했다는 점이 흥미로웠습니다. 또한, 모델에 쓰인 네트워크 구조가 그림으로 잘 표현되어 입력값과 그것이 어떻게 처리되고 결과값이 어떤 형태인지 쉽게 쓰여있어서 이해하기 쉬웠습니다. 사진이 제공되어서 연구의 과정과 결과를 알아보기가 유용했습니다.
기존에는 point-based detection이 거의 활용되지 않았었는데, 다른 분야의 기술을 객체 탐지에서 적절히 활용한다는 점을 보고, 저도 다른 분야에서 활용되는 기술들에 관심을 기울이고 객체 탐지에 어떻게 하면 잘 활용할 수 있을까 고민해봐야 겠다는 생각이 들었습니다.
또한, 점의 위치는 크게 중요하지 않다는 점이 labeling cost를 줄이는데 큰 기여를 한다고 생각합니다. 다만, 제가 라벨링하려고 하는 헬멧이나 safety harness 같은 경우는 크기가 잘 보이지만, 안전 연결선의 경우 얇은 경우가 많은데 점을 통해서도 학습이 가능한지 의문이 들었습니다.
아쉬운 점은 본 연구에서는 relative regression을 사용하였고, 기존의 모델은 absolute regression을 사용하여서 본 모델의 경우 점과 바운딩 박스간 매칭 에러가 줄었다는 점에 대한 이유가 밝혀지지 않아서 아쉬웠습니다. 그리고, weakly labeled images가 전체 이미지 중 어느 정도를 차지해야 하는지 최적의 비율도 나중에 연구해봐야 할 것 같습니다. 추가로, point annotation된 이미지가 pseudo bouding box를 만드는 과정이 수도코드와 같이 좀 더 자세히 서술되었다면 좋았을 것 같습니다.
Author Information
Doil Kim
Affiliation : Master Course in KAIST KSE program
Research Topic : Data science, Object detection, Human factors
6. Reference & Additional materials
Reference :
Points as Queries: Weakly Semi-supervised Object Detection by Points
https://arxiv.org/abs/1612.03144
https://wikidocs.net/145910
Last updated